
Potrzeba matką wynalazku
Ostatnio pisząc testy jednostkowe zauważyłem, że bardzo często powtarzam schemat „Napisz test” -> „Skopiuj test” -> „Zmień wartość w skopiowanym teście tak, by przetestować warunek odwrotny” -> „Zmień opis na odwrotny”.
W praktyce wygląda to mniej więcej tak:

Pomyślałem, że mogę nieco usprawnić ten proces, a przy okazji nauczyć się czegoś nowego – wpadłem więc na pomysł, że stworzę plugin do mojego ulubionego edytora – Sublime Text 3.
Plugin ten ma mieć jedno bardzo proste zadanie, a mianowicie zamienianie angielskich zdań w trzeciej osobie liczby pojedynczej z twierdzących na przeczące i na odwrót.
Ale od czego mam zacząć?
Skoro pomysł już jest, to teraz wystarczy go zrealizować, prawda? Problem jest tylko taki, że nie mam pojęcia, jak pisać pluginy do ST3. Szybkie googlowanko zaprowadziło mnie do tego artykułu. Stamtąd dowiedziałem się, że pluginy są po prostu pythonowymi klasami dziedziczącymi po sublime_plugin.TextCommand i odpalane są przez interpreter Pythona wbudowany w Sublime’a. Nie byłem tym zachwycony, bo nigdy nie pisałem w tym języku, jednak odnalazłem w nim sporo analogii do ruby’ego, a z większością problemów wynikających z nieznajomości API lub składni mogłem się uporać dzięki kochanemu StackOverflow.
Mimo że głównym elementem mojego pluginu są operacje na stringach, potrzebowałem również zapoznać się z podstawami API Sublime’a (Dokumentację można znaleźć tutaj). Interfejs nie jest super intuicyjny, ale do mojego celu wystarczyło zrozumieć kilka konceptów:
- klasa View – reprezentuje okienko edytora. W momencie, gdy nasz ekran podzielony jest na kilka okien edycji wywołanie self.view w klasie naszego plugina zwróci okienko, w którym aktualnie jest kursor.
- Klasa Edit – jej instancja przekazywana do każdej komendy (pluginu) w sublimie. Nie posiada ona żadnych metod publicznych i służy grupowaniu zmiar bufora, czyli w praktyce umożliwia użytkownikowi np. cofnięcie lub ponowienie zmian wprowadzonych przez nasz plugin.
- Klasa Region – reprezentuje wycinek tekstu. Jest to w zasadzie tablica dwóch liczb + kilka pomocniczych metod.
Po zapoznaniu się z tutorialem i podstawami API Sublime’a zacząłem zastanawiać się, jak napisać mój plugin…
Krok 1 – szukamy zdania w linii
Pierwszą rzeczą, którą musi zrobić nasz program będzie znalezienie w linii, w kórej aktualnie znajduje się kursor Regionu obejmującego zdanie w pojedynczych (‚ ‚) lub podwójnych (” „) apostrofach. Aktualna pozycja kursora musi zawierać się w tym regionie. Postanowiłem, że najlepiej do tego sprawdzi się wyrażenie regularne.
Przy budowaniu wyrażeń regularnych bardzo przydatna jest strona https://pythex.org/ – zaoszczędziłem dzięki niej mnóstwo czasu.
Zacząłem od następującego wyrażenia:
(\”.*\”|(\’.*\’))
To wyrażenie jest niezłe, bo pozwala na dopasowanie zarówno do pojedynczych, jak i podwójnych apostrofów ale ma jedną wadę – jest „zachłanne”. Oznacza to, że w wypadku, gdy linia zawiera kilka stringów w apostrofach nasze wyrażenie znajdzie cały ciąg znaków znajdujący się pomiędzy pierwszym i ostatnim apostrofem w danym zdaniu. Czyli zamiast „It requires a name” and „It requires a surname„ wyszuka „It requires a name” and „It requires a surname”. Na szczęście python posiada proste narzędzie, pozwalające to naprawić:
(\”.*?\”|(\’.*?\’))
Teraz wyrażenie działa tak, jakbyśmy tego oczekiwali.
Niestety moja radość nie trwała długo – kolejnym problemem, na który się natknąłem, był fakt, że moje wyrażenie nie radzi sobie z tzw. escaped quotes, czyli z pojedynczym apostrofem poprzedzonym znakiem backslash. Tutaj znowu python daje radę – zgodnie z regular expression cheatsheet ze strony pythex.org aby odfiltrować apostrofy poprzedzone backslashem można wykorzystać negative lookbehind assertion:
(?<!…)
Finalnie wyrażenie wygląda tak:
(\”.*?\”|((?<!\\)\’.*?(?<!\\)\’))
Po zbudowaniu odpowiedniego wyrażenia musiałem już tylko spośród dopasowanych ciągów znaleźć taki, którego region zawiera pozycję kursora:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def find_quotes(self): | |
| quotes_regex = r'(\".*?\"|((?<!\\)\'.*?(?<!\\)\'))' | |
| iterator = re.finditer(quotes_regex, self.current_line()) | |
| for match in iterator: | |
| quote_span = match.span() | |
| region = sublime.Region(quote_span[0] + self.current_line_start(), quote_span[1] + self.current_line_start()) | |
| if region.contains(self.cursor_position): | |
| return (quote_span[0], quote_span[1]) |
Krok 2 – negujemy zdanie
Po znalezieniu zdania będziemy chcieli zamienić je na przeczące. Metoda, którą wymyśliłem jest dość naiwna, ale jak dobrze wiemy jeżeli coś jest głupie a działa, to nie jest głupie 🙂
Najpierw przeanalizujmy sobie, jakie są możliwe czasowniki w czasie present simple dla podmiotów w 3. osobie i liczbie pojedynczej i w jaki sposób je zanegować:
- Czasownik nieregularny „is” -> aby zanegować dodajemy „not”
- Czasowniki modalne – „should” -> „shouldn’t”, „must” -> „mustn’t”, „has to” -> „does not have to”
- Pozostałe czasowniki – czasownik+s -> does not czasownik z wyjątkami:
- Czasowniki kończące się na -ies negujemy poprzez zamiane –ies na -y (np. flies -> does not fly). Specjalnym przypadkiem są słowa, które w formie bezokolicznikowej kończą się -ies (np. lies -> does not lie).
- Czasowniki kończące się na -es poprzedzone zgłoskami „ss”, „x”, „ch”, „sh”, „o” negujemy poprzez usunięcie całej końcowki -es (np. goes -> does not go, misses -> does not miss)
Kod klasy SentenceNegator wygląda następująco:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class SentenceNegator: | |
| IRREGULAR_ES_VERB_ENDINGS = ["ss", "x", "ch", "sh", "o"] | |
| CONSONANTS = ['a', 'e', 'i', 'o', 'u', 'y'] | |
| def negate(self, sentence): | |
| # is | |
| if sentence.find("isn't") > -1: | |
| return sentence.replace("isn't", "is") | |
| if sentence.find("isn\\'t") > -1: | |
| return sentence.replace("isn\\'t", "is") | |
| if sentence.find("is not ") > -1: | |
| return sentence.replace("is not ", "is ") | |
| if sentence.find("is ") > -1: | |
| return sentence.replace("is ", "is not ") | |
| # has | |
| if sentence.find("does not have") > -1: | |
| return sentence.replace("does not have", "has") | |
| if sentence.find("doesn't have") > -1: | |
| return sentence.replace("doesn't have", "has") | |
| if sentence.find("doesn\\'t have") > -1: | |
| return sentence.replace("doesn\\'t have", "has") | |
| if sentence.find("has ") > -1: | |
| return sentence.replace("has ", "does not have ") | |
| # should | |
| if sentence.find("shouldn't") > -1: | |
| return sentence.replace("shouldn't", "should") | |
| if sentence.find("shouldn\\'t") > -1: | |
| return sentence.replace("shouldn\\'t", "should") | |
| if sentence.find("should not") > -1: | |
| return sentence.replace("should not", "should") | |
| if sentence.find("should") > -1: | |
| return sentence.replace("should", "should not") | |
| # must | |
| if sentence.find("mustn't") > -1: | |
| return sentence.replace("mustn't", "must") | |
| if sentence.find("mustn\\'t") > -1: | |
| return sentence.replace("mustn\\'t", "must") | |
| if sentence.find("must not") > -1: | |
| return sentence.replace("must not", "must") | |
| if sentence.find("must ") > -1: | |
| return sentence.replace("must ", "must not ") | |
| # can | |
| if sentence.find("can't") > -1: | |
| return sentence.replace("can't", "can") | |
| if sentence.find("can\\'t") > -1: | |
| return sentence.replace("can\\'t", "can") | |
| if sentence.find("cannot") > -1: | |
| return sentence.replace("cannot", "can") | |
| if sentence.find("can ") > -1: | |
| return sentence.replace("can ", "cannot ") | |
| # doesn't work -> works | |
| doesnt_regex = r'(doesn\'t|doesn\\\'t|does not) (?P<verb>\w+)' | |
| if re.search(doesnt_regex, sentence): | |
| def replace_doesnt(matchobj): | |
| verb = matchobj.group(2) | |
| if verb.endswith("y") and self.__is_consonant(verb[-2]): | |
| return "{0}ies".format(verb[0:-1]) | |
| for ending in self.IRREGULAR_ES_VERB_ENDINGS: | |
| if verb.endswith(ending): | |
| return "{0}es".format(verb) | |
| return "{0}s".format(verb) | |
| return re.sub(doesnt_regex, replace_doesnt, sentence, 1) | |
| verb_regex = r'(It |it |)(?P<verb>\w+)s( |$)' | |
| # works -> does not work | |
| def replace_verb(matchobj): | |
| subject = matchobj.group(1) | |
| verb = matchobj.group(2) | |
| whitespace = matchobj.group(3) | |
| # flies -> fly, but not die -> dy | |
| if verb.endswith("ie") and len(verb) > 3: | |
| verb = "{0}y".format(verb[0:-2]) | |
| # stresses -> stress | |
| for ending in self.IRREGULAR_ES_VERB_ENDINGS: | |
| if verb.endswith("{0}e".format(ending)): | |
| verb = verb[0:-1] | |
| return "{0}does not {1}{2}".format(subject, verb, whitespace) | |
| if re.search(verb_regex, sentence): | |
| return re.sub(verb_regex, replace_verb, sentence, 1) | |
| return sentence | |
| def __is_consonant(self, letter): | |
| return letter not in self.CONSONANTS |
Zasada jest prosta – dla wyżej wymienionych typów czasowników należy wykonać takie kroki:
- Jeśli zdanie zawiera przeczenie czasownika danego typu zaneguj go i zwróć zdanie pozytywne
- Jeśli zdanie nie zawiera przeczenia, to znajdź niezanegowany czasownik i spróbuj go zanegować
- Jeśli zdanie nie zawiera czasownika (nie jest zdaniem) – zwróć wejściowy ciąg znaków
Warto wspomnieć, że takie podejście sprawdzi się tylko dla zdań jednokrotnie złożonych, niezawierających conditionali. Czyli np. „It has a value” zostanie poprawnie zmienione w „It does not have a value”, ale już „It has a value if other value is 0” może dać nieoczekiwany rezultat, czyli: „It has a value if other value is not 0”. W takim przypadku nasz program musiałby znać kontekst zdania, żeby móc je poprawnie zanegować.
Krok 3 – piszemy testy jednostkowe
Pierwszą rzeczą jaką zrobiłem zaraz po zapoznaniu się z API Sublime’a było zadanie sobie pytania „jak mam to przetestować?”. Stwierdziłem, że przy mojej niskiej znajomości Pythona szansa na wprowadzenie błędu przy którejś z kolei zmianie jest całkiem duża, a dobre pokrycie testami da mi pewność, że nic po drodze nie zepsuję (poza tym to po prostu dobra praktyka).
Tutaj z pomocą przyszła mi biblioteka https://github.com/randy3k/UnitTesting. Działa ona w bardzo prosty sposób – symuluje realne użycie naszego pluginu poprzez stworzenie nowego okienka edytora i wykonanie naszej komendy. Po odpaleniu komendy możemy sprawdzić czy tekst w oknie testowym jest zgodny z oczekiwanym.
Plik z zestawem testów należy umieścić w folderze tests naszej paczki.
Przykładowy plik z testem jednostkowym wygląda tak:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import sublime | |
| import sys | |
| from unittest import TestCase | |
| class TestNegateSentence(TestCase): | |
| def setUp(self): | |
| self.view = sublime.active_window().new_file() | |
| # make sure we have a window to work with | |
| s = sublime.load_settings("Preferences.sublime-settings") | |
| s.set("close_windows_when_empty", False) | |
| def tearDown(self): | |
| if self.view: | |
| self.view.set_scratch(True) | |
| self.view.window().focus_view(self.view) | |
| self.view.window().run_command("close_file") | |
| def test_negate_is(self): | |
| self.check_substitution('"The dog is black"', '"The dog is not black"') | |
| def check_substitution(self, input, expected): | |
| self.set_text(input) | |
| self.view.run_command("negate_sentence") | |
| self.assertEqual(self.get_text(), expected) | |
| def set_text(self, string): | |
| self.view.run_command("insert", {"characters": string}) | |
| def get_text(self): | |
| return self.view.substr(self.view.line(self.view.text_point(0, 0))) | |
| def move_cursor(self, position): | |
| pt = self.view.text_point(0, position) | |
| self.view.sel().clear() | |
| self.view.sel().add(sublime.Region(pt)) |
Krok 4 – dodajemy CI i pokrycie testami
Po dodaniu testów do projektu pomyślałem, że fajnym usprawnieniem będzie automatyczne uruchamianie testów w którymś z serwisów umożliwiających CI. Okazało się, że w repozytorium https://github.com/randy3k/UnitTesting można znaleźć gotową konfigurację do systemu Travis CI. Integracja z Travis CI odbyła się bezboleśnie – już pierwszy build zaświecił się na zielono.
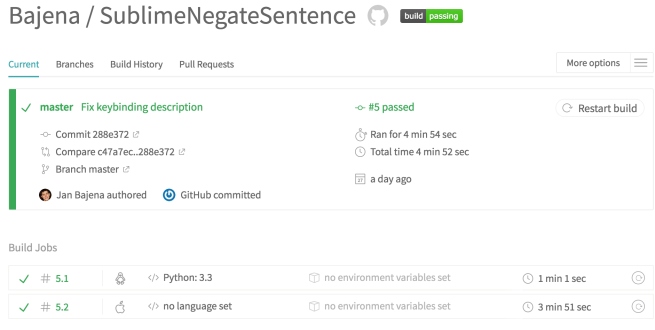
Poza integracją z CI postanowiłem również zintegrować się z codecov – serwisem pokazującym w jakim stopniu nasz projekt jest pokryty testami. Ponownie okazało się to banalne, ponieważ plik .travis.yml zawiera konfigurację, która automatycznie generuje plik z pokryciem testami. Jedyne co musiałem zrobić, to zalogować się w codecov.io i wskazać odpowiednie repozytorium z GitHuba.
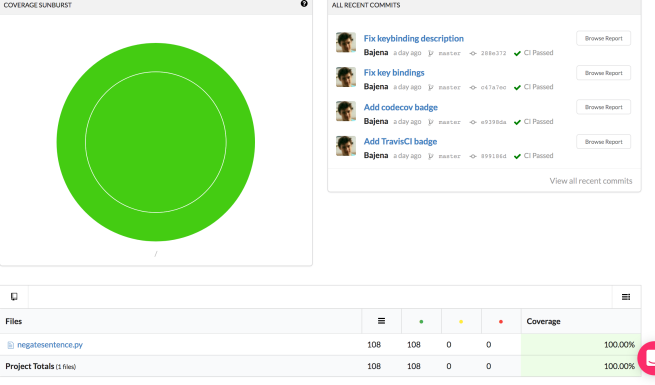
Dzięki dodaniu ciągłej integracji i pokrycia testami mam pewność, że każda linia jest przetestowana, a mój projekt działa jak należy.
Oprócz tego zyskałem też takie czadowe badge, które dodałem do repozytorium w GitHubie:

Krok 5 – sprawdzamy plugin w akcji
Czas zobaczyć plugin w akcji. Można go przetestować wykorzystując jeden ze sposobów:
- Na wybranym zdaniu nacisnąć kombinację klawiszy „^ + ⌘ + ⇧ + n” na Macu lub „CTRL + SHIFT + ALT + n” na windowsie/linuxie.
- Nacisnąć „⌘ + ⇧ + P” i w okienku poleceń wybrać NegateSentence
Poniżej mała prezentacja:
Podsumowanie
Napisanie własnego pluginu do edytora, w którym codziennie spędza się po 8 godzin daje sporą satysfakcję, nawet jeżeli jest to super proste narzędzie.
Poza samą satysfakcją takie proste zadanko idealnie sprawdziło się jako poligon służący do nauki Pythona. Dwie pieczenie na jednym ogniu!
Całość projektu można znaleźć pod adresem https://github.com/Bajena/SublimeNegateSentence
